

How auto coding sentiment works
This feature is available in NVivo Plus edition. Learn more
This topic explains how NVivo analyzes sources to determine sentiment coding. Text analytics is a complex process—human perception of sentiment is always going to be more accurate.
We aim to continually enrich this functionality and we invite you to share your suggestions with us on the NVivo forum.
In this topic
- The process
- Limitations of sentiment auto coding
- Sentiment scoring
- Coding examples
- Mixed sentiment coding
The process
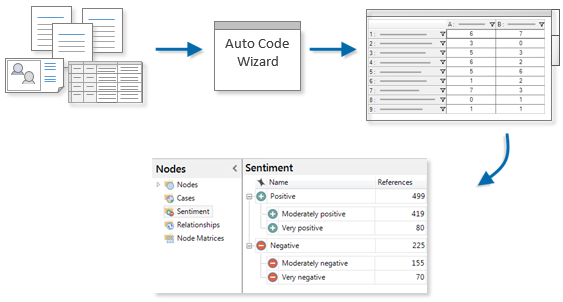
Select multiple sources, nodes or cases and use the Auto Code Wizard to produce results. A node matrix is created, and content is coded to sentiment nodes.

Limitations of sentiment auto coding
NVivo searches for expressions of sentiment in the source material.
It is important to understand that this tool does not classify content according to sentiment. It does not take each piece of content and rate it on a Likert sentiment scale. It looks at the sentiment of words in isolation—the context is not taken into account.
Like most text analysis tools, NVivo cannot recognize:
-
sarcasm
-
double negatives
-
slang
-
dialect variations
-
idioms
-
ambiguity
Sentiment scoring
The process uses a scoring system. Each word containing sentiment has a pre-defined score. Each sentiment node represents a range on a scale (of sentiment).

-
The score for each word determines the sentiment node it is coded to.
-
The score of words can change if they are preceded by a modifier (for example, more or somewhat) which intensifies the sentiment.
-
Words with a score that fall within the neutral range are not coded.
Coding examples
Example 1 - Simple sentiment
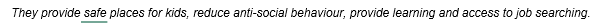
In this example, the word safe has a score which falls within the moderately positive range, so it is coded at the sentiment node Moderately Positive.
Example 2 - Multiple words of the same sentiment
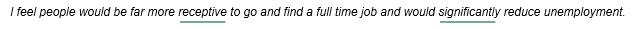
In this example, the word receptive has a score which falls within the moderately positive range, and the word significantly has a score which falls within the very positive range. When a sentence contains multiple positive or multiple negative words, the sentence is coded at the most extreme child node for that sentiment. In this example, the sentence is coded at the sentiment node Very Positive.
Example 3 - Both positive and negative sentiment
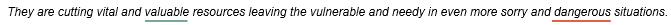
In this example, the word valuable has a score which falls within the moderately positive range, and the word dangerous has a score which falls within the moderately negative range. This sentence is coded at the sentiment node Moderately Positive and the sentiment node Moderately Negative.
Example 4 - Neutral sentiment
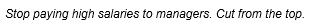
In this example, the word top has a sentiment score that falls within the neutral range on the scale—so the sentence is not coded at any sentiment node.
Example 5 - No sentiment
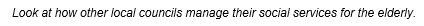
In this example, there is no sentiment detected in any word—so the sentence is not coded at any sentiment node.
Mixed sentiment coding
It's possible to have the same sentence coded at positive and negative sentiment nodes—because the analysis process looks at words in isolation.
You can easily identify content coded at multiple nodes by running a coding query.
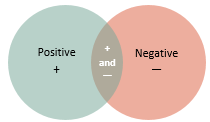
When reviewing the results of this query, you might choose to uncode some of the references at one of the sentiment nodes using coding stripes.
NVivo won't code the same content at multiple positive or multiple negative nodes.