

About coding
Coding is a fundamental task in most qualitative projects—it involves gathering all the material about a particular theme or case into a node for further exploration. This topic provides an overview of coding and introduces possible approaches.
In this topic
- What is coding?
- Deciding on an approach
- 'Broad-brush' coding using queries
- Coding in sources
- Coding entire sources to a node
- Auto coding structured content
- Auto coding using existing patterns
- Automatically detect and code themes or sentiment
- Making sure team members code consistently
- 'Coding on' in a node
What is coding?
'Coding' your sources is a way of gathering all the references to a specific topic, theme, person or other entity. You can code all types of sources and bring the references together in a single 'node':
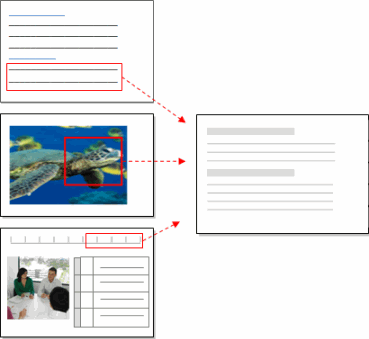
The process of coding can generate ideas and help you to identify patterns and theories in your research material.
For example, you could gather all the negative opinions about a policy and examine them together in a node—from there, you could tease out common threads and ask questions like What do young people think and do their opinions differ from those of older people?
You can also code to gather source content at nodes that represent the subjects of your research, such as people or places. For example, if you have survey responses from a class of students, you can create a case node to represent each student, and then code their opinions at their case node.
You can code manually within a source or do some fast coding using the auto code and query-based coding features.

Deciding on an approach
The way you approach the analysis of sources can depend on the
- Methodology you are using (if any)
- Amount and type of data you have
- Time available
NVivo does not prescribe an approach but provides the tools to let you work the way that suits you best. For example, if you have many sources or you have large dataset sources—make the most of NVivo's auto coding and query-based coding features. If you have a smaller number of sources that require close analysis—take advantage of the easy-to-use coding techniques.
You can create a node structure and then code your material at the 'ready-made' nodes or you can create nodes as you work through your source materials.
'Broad-brush' coding using queries
You can use NVivo queries to automatically code your sources based on the words or phrases they contain. This can be a useful starting point for reviewing your data.
For example, you can
- Run a Word Frequency query to see (and code) the words that occur most often—for example, if the word literacy appears frequently you can save all occurrences in a node for further investigation
- Run a Text Search query on a specific word or phrase and automatically code the text that is found—for example, find and code all the occurrences of climate change.
Refer to Run a Word Frequency query and Run a Text Search query for detailed instructions.
Coding in sources
While working in a source you can select content and then code it at new or existing nodes.
NVivo provides the following ways to code your sources:
-
Select and code content using the options on the Analyze tab of the NVivo ribbon.
-
Drag and drop selected content on a node in List View. You can customize your workspace to make the most of drag and drop coding—list the nodes on the left and display your source on the right:

-
Right-click to access options on the shortcut menu.
-
In vivo code to make a new node from selected words or phrases.
-
Quick code using nicknames for common nodes—for example desalination could have the nickname desal. You select the content you want to code and enter or select the nickname.
When you successfully code the content in a source, a confirmation message is displayed in the NVivo status bar.
The content available for coding depends on the type of source you are working with, refer to the following topics for more information:
- Basic coding in documents, externals and memos
- Basic coding in picture sources
- Basic coding in audio and video sources
- Basic coding in dataset sources
Coding entire sources to a node
You can code entire sources to new or existing nodes. This can be useful, if you want to code everything in the source to a particular theme node, or if the source represents the responses of an individual and you want to code it all at their case node.
If you select a source in List View or have a source open in Detail View, you can code the entire content at a new or existing node—refer to Coding techniques (code entire sources at a node).
You can also code an entire source at a new node if you create nodes automatically when importing source materials. You can:
-
Use Evernote tags to create and code at nodes—refer to Import from Evernote (Understand how Evernote tags are converted to nodes).
-
Specify nodes to code to when you capture web pages—refer to Import web pages.
When you code entire sources, the content is coded as described below:
| Source type | How the content is coded |
| Documents | All the text (and any images) in the document are coded as a single coding reference. |
| PDFs | All the text in the
PDF is coded as a single coding reference.
Each page of the PDF is also coded as region (image). For example, a two page PDF (which contains text) will be coded as three separate coding references—one for the text, and one for each page. |
|
Datasets |
The content of each
codable cell in the dataset is coded as a separate coding reference.
If the dataset contains source shortcuts, the content of the destination source is also coded entire to the node. |
|
Audio and Video |
The media is coded
as a single coding reference.
If there is a transcript, the content of each cell in the Content column is coded as a separate coding reference. |
|
Pictures |
The entire picture is coded to
the node.
If there is a log, the content of each cell in the log is coded to the node as a separate coding reference. |
Auto coding structured content
This feature is available in NVivo Pro and NVivo Plus.
If you are working with structured source material, auto coding provides a fast way to organize it into nodes—for example, if you have interviews that contain the same questions (and are consistently structured), you can gather the answers to each question in a node.
Auto coding can be used to reorganize a wide range of materials—from focus group transcripts to survey responses or any material that has a consistent structure. You can auto code the following:
- Paragraph styles If you have applied paragraph styles consistently in your document sources, you can use them to auto code. For example, you could make nodes for each question in an interview and code the responses. Refer to Automatic coding in document sources for more information.
- Structured paragraphs You can auto code your document sources by paragraph if they are tightly structured—for example, where each paragraph explores a different theme. NVivo makes a node for each paragraph and uses the paragraph number as the node name. Refer to Automatic coding in document sources for more information.
- Datasets If you have a dataset, your data is structured into rows and columns. NVivo provides automated tools that allow you analyze large amounts of data quickly. Refer to Automatic coding in dataset sources for more information.
- Custom field (columns) in audio or video transcripts For example, if you have added the custom field Speaker, NVivo can create a node for each speaker and code the content at the node. Refer to Automatic coding in audio and video sources for more information.
-
Ranges Where your sources are already structured by theme or topic you may want to use range coding. For example, code paragraphs 1-5 at the node conservation or transcript rows 2-4 at the node sanctuary. Range coding also supports paper-based coding—for example, you can print out a document with the paragraph numbers displayed, mark up the text to code and then range code in NVivo. Refer to Range code your sources for more information.
NOTE If your materials are not structured, you can use other NVivo features to help you with coding. For example, you could run a Word Frequency query to see what words are commonly being used in a collection of sources. You could also use a Text Search query to search for terms and automatically save the results in a node.
Auto coding using existing patterns
This feature is available in NVivo Plus.
Pattern-based auto coding is an experimental feature that you can test and try out. This feature is designed to speed up the coding process for large volumes of textual content.
When you auto code using existing patterns, NVivo compares each text passage—for example, sentence or paragraph—to the content already coded to existing nodes. If the content of the text passage is similar in wording to content already coded to a node, then the text passage will be coded to that node.
Pattern-based auto coding is an experimental feature that may work better for some projects than others. Before you use this feature and for more information, refer to the topic Automatic coding using existing coding patterns.
Automatically detect and code themes or sentiment
This feature is available in NVivo Plus.
If you are working with large volumes of data, or have limited time, you can quickly identify broad themes and sentiment in your sources using the Auto Code Wizard.
This process uses a different engine to pattern-based coding—it uses linguistic processes and a specialized sentiment dictionary to produce results.
Automated insights may work better for some projects than others. For more information, refer to About automated insights.
Making sure team members code consistently
If multiple researchers are coding the same material, you may be interested in the consistency of their coding.
To help team members understand the meaning of nodes, create a codebook that lists the nodes and their descriptions—refer to Export a codebook for more information.
NVivo provides a number of ways to check consistency or coder reliability:
- Run a Coding Comparison Query to determine the percentage of agreement and disagreement between coders.
- Display coding stripes for users—open a source and see the coding done by each researcher.
- Filter the content of a node to see only the references coded by selected researchers
Remember that inconsistency in coding is not necessarily negative—it may prompt productive debate and deeper insights into the data. Refer to Run a coding comparison query, Use coding stripes to explore coding, or Review the references in a node (See the coding for a selected user).
'Coding on' in a node
When you open a node, you can explore the references gathered there. As you make new discoveries, you may want to code the content at other nodes—this is called 'coding on'. You can use the same coding techniques that you use to code a source.
You can also 'code on' in a node by: